Helping machines ‘learn’ and be more useful: An introduction to Machine Learning
Dr. Pradeep Kumar S, July 2022
Today, technology powers some of the most delightful experiences in your favorite apps and products. It helps organize your photos, understand your voice commands, show you the most relevant reviews for products and businesses, navigate from one place to another, and much more. If you are wondering what goes on behind the scenes or want to understand how technology can perform these wonderful tasks, you are in for a treat! Read on about what has become an integral part of your day-to-day life.
Machine Learning: An overview
Artificial Intelligence (AI) is the science of making machines “smarter”. Machine Learning (ML) is a subset of AI focused on the ability of machines to receive data and learn for themselves. ML can help machines recognize patterns and adjust to unique situations, without specific programming. This helps build faster and more customized user experiences online.
ML is powered by algorithmic models that are trained to recognize patterns in collected data (such as logs, speech, text, or images). Then they can apply what they have learned from existing data to forecast future behaviors, outcomes, and trends to solve problems. For example, an algorithm can be trained with dog photos to recognize dogs; the same algorithm can also be trained with bicycle photos to recognize bicycles with minimal changes to the code.
"Any sufficiently advanced technology is indistinguishable from magic"
- Arthur C. Clarke
From helping farmers in Japan to sort cucumbers to assisting doctors in India as they diagnose eye disease, ML is changing the way people use code to solve problems and improve lives.
Why is ML popular now?
The key algorithms powering machine learning were created decades ago. They come from disciplines like statistics, linear algebra, biology, physics. Today, ML has become an important tool to solve difficult computational problems, and its popularity has surged in the recent past due to Big Data, the increased computing power of technology, availability of Cloud infrastructure, and advanced algorithms that can analyze the data to solve problems.
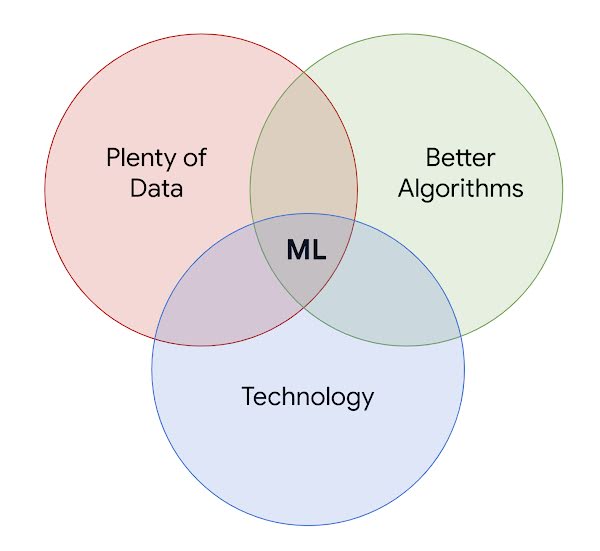
Data is key to ML. The more diverse the data that ML models train on, the better the predictions. Advances in Computer Science and better algorithms make the machine learn better and faster.
Because of this availability of data, algorithms, and technology, ML-based approaches can solve complex problems that rule-based approaches can’t.

In the above example, we see how the ML approach will ‘learn’:“what is a carrot” by trial and error, and this approach can be quickly developed, deployed, and can show an impact on a global scale with a fraction of the resources required otherwise.
That’s great. But how does Machine Learning work?
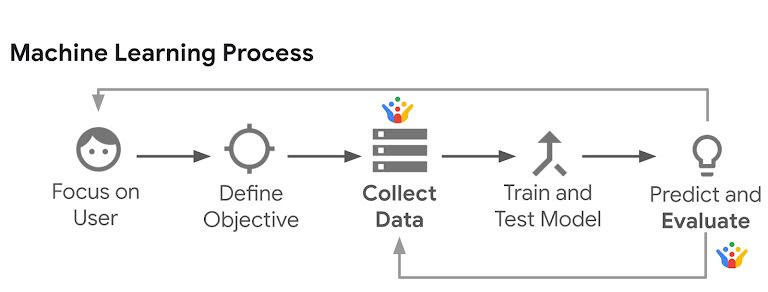
1. Focus on the user: As with any good product development philosophy, the ML process also starts with understanding the user's needs or wants. Not every problem needs ML to be solved, and conversely, ML can’t solve every problem. Only user problems that are too complex to solve by traditional programming / rule-based systems, and deal with a specific user need, that can be solved by computers ‘learning’ themselves about the problem, should be identified and analyzed for the next stage.
2. Define the objective: Clearly define the problem statement. i.e Problem-framing. For example, your objective could be to predict which friends a user is likely to share a photo with or to suggest where a user should eat in a new city based on the history of the restaurants they have visited in the past. Your goals should quantify success metrics as well.
3. Collect data: Identify the input data that your ML model needs, to make successful predictions. Since ML models learn from examples to recognize patterns, it is essential to find a large existing source of data that is relevant to your problem. Experts say, collecting, cleaning, exploring, and other data processes tend to be the longest but most critical part of the process. The better you know your data, the more useful hypothesis you can make.

Did you know?
The collection and labeling of data are the biggest parts of creating ML-based products. The end-users of these products will not see these labels and they may not immediately understand how a certain behavior of the ML-based product is a consequence of the data fed (or not fed) to the ML model. For example, if a bad restaurant review with a sarcastic “praise” of the service gets served to a reader as a positive review, users won’t be able to fully understand the cause of that error by the ML system. ML products are only as good as the data that they train on. With this context, a diverse set of inputs leads to better products for more people.
4. Train and test the model: Once the data has been collected, the model is trained. Part of the data (called training data) is fed into the algorithm to predict outcomes, and the outcomes are compared to ‘ground truth’ (i.e. data that is known to be correctly identified and labeled). This repeated process runs thousands, sometimes millions of times and when the error reaches the minimal threshold set by the team, the model is ready to be tested. It is then tested on the rest of the data (called test data) to validate the model and make it ‘ready for implementation’. In short, a test set is a data set used to evaluate the model developed from a training set.
5. Predict and evaluate: Once the ML model is rolled out, it will continue to be refined and improved with every user interaction. This is an ongoing step in the ML development process and the iteration takes us back to step 3 (data collection) or step 1, depending on the outcome and progress.
Try it out yourself
‘Teachable machine’ is a fast and easy way to create machine learning models using your own images, videos and sounds. You don’t need any coding skills to use this tool. Try it out here.
Crowdsource community - this is where we shine!
Crowdsource and the Crowdsource community plays a very important role in step 3 (data collection and improving diversity and representation in the data) and step 5 (evaluation of the ML output). Crowdsource gives anyone the opportunity to play a role in the training process. On Crowdsource, anyone can label images, translate handwritten text in a variety of languages, and validate the sentiment of written sentences, which serve as the data that helps to train ML models to recognize patterns. With tasks like “Image Capture,” and “Smart Camera” users get to participate in the actual production of data. A user can even choose to donate their images to Open Source so that the whole developer and research community can advance the state of the art of technology, with diversity in mind. At the evaluation phase, Crowdsource contributions are valuable to debugging biases and building better performing models that will be more user-friendly.
Key concerns and where Crowdsource plays an important role
The ML model is only as good as the examples. Machine learning models face two important limitations: 1) bias and 2) variety.
Machine learning models are not inherently objective. Engineers train models by feeding them a data set of training examples. Human involvement in the provision and curation of this data can make a model's predictions susceptible to bias.
When building models, it's important to be aware of common human biases that can appear in your data, so you can take proactive steps to mitigate their effects.
A biased data sample will teach the algorithm to look for similar patterns and hold them ‘true’. These biases limit the usability of the algorithm, especially in a global context. For example, a company’s AI recruitment tool heavily favored men for the job openings because the 10-year dataset they used to measure whether a candidate would be a good fit for the job mostly came from men, a reflection of the male dominance across the tech industry. Similarly, the lack of variety will cause the model to have a very narrow view of what it is supposed to predict. For example if all of the examples of cats have triangle-shaped ears, it might fail to recognize a cat which has flat / no prominent ears.
The Crowdsource community plays an important role as a driver of diversity of data for the ML models in Google, to help remove biases and add variety, to make our products more inclusive and help us serve everyone, everywhere.

If you’re new here, you can get started at the main Crowdsource website or download our Android app. We would love to hear your feedback and thoughts. Please feel free to write to us on Facebook or find us on Twitter using #GoogleCrowdsource.
This blog post is a recap of our ‘Introduction to Machine Learning’ on On Air with Crowdsource - a series of virtual learning sessions with Googlers about a variety of topics. These sessions help our influencers and top contributors from around the world to build their knowledge and skill sets through practical learning. Due to the overwhelmingly positive response that these sessions have received, we’re super excited to now make this content available to all of our readers.
Try Crowdsource. Make a difference.

Back to top